V posledním článku jsme slíbili přiblížit proces implementace prediktivní údržby se zapojením umělé inteligence. A právě to teď uděláme! I když se proces pokaždé trochu liší, existují určité kroky, které musí být vždy dodrženy.
Je důležité poznamenat, že tento proces je zacyklený, což znamená, že pokud jsou výsledky celého cyklu neuspokojivé, bude potřeba zkontrolovat každou fázi.
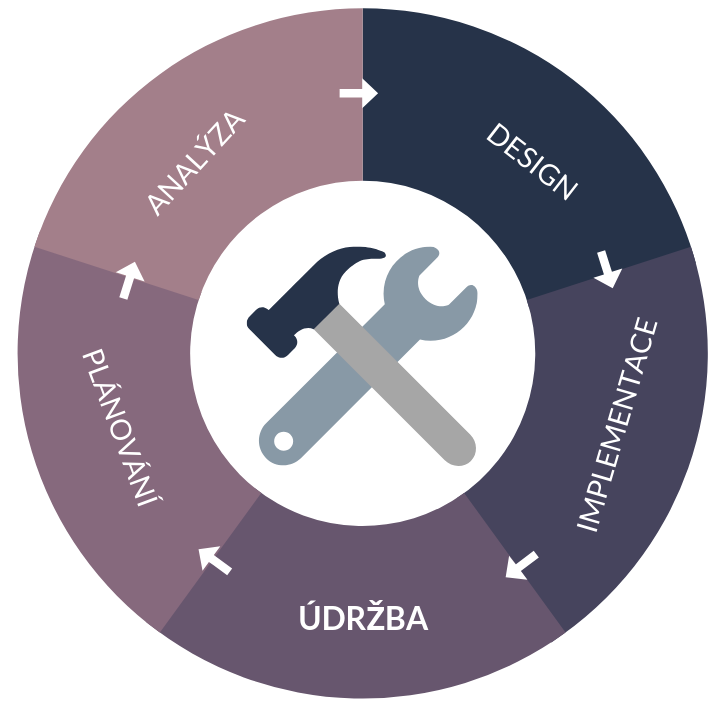
Fáze 1: Sběr a analýza dat
Přesná analýza vyžaduje odpovídající údaje. V závislosti na zařízení, které chceme otestovat, používáme různé sady senzorů, které sledují jeho technický stav. Údaje, které shromažďujeme, poskytují vhled a vykreslují korelace mezi hodnotami a skutečným stavem zařízení. Abnormality musíme sledovat a zaznamenávat dříve, než dojde k poruše zařízení.
V dalším kroku musíme najít nejefektivnější sadu parametrů pro náš model. Nepodstatné parametry by snížily přesnost modelu, protože by se učily ze zbytečných dat. Jakmile vybereme správné parametry, musíme z dat odfiltrovat „šum“.
Je důležité vybrat správné atributy, abychom se vyhnuli nesprávným indikacím ze senzorů. Například, když senzor měří teploty, je výsledek -200 °C zjevně nesprávný a měli bychom ho ignorovat. Data musíme připravit způsobem, který umožňuje využití strojového modelu učení, což znamená, že data musí mít správný formát. Síť vyžaduje vstupní (požadavky) a výstupní data (zpětnou vazbu) a neúplné výsledky musíme odfiltrovat.
Poslední věc, kterou zbývá udělat, je rozdělit data do dvou skupin: tréninková a testovací data. Stejné datové sady nelze použít jak pro učení, tak pro vyhodnocování, protože by se umělá inteligence naučila správné odpovědi a „podváděla by“.
Fáze 2: Tvorba předpovědního modelu a jeho vývoj
Jakmile máme připravenou sadu dat pro použití algoritmů umělé inteligence, je čas zvolit vhodný model hlubokého učení. Pomocí předem určených parametrů se snažíme vytvořit co nejpřesnější model. K tomu používáme celou řadu kritérií a pravidel. Pro účely prediktivní údržby jsou zvláště užitečné metody, které silně penalizují velké výpočetní chyby. Střední kvadratická odchylka pomůže určit hodnotu zbývajícího užitného života (Remaining Useful Life – RUL) s maximální přesností predikce.
S testovaným, vylepšeným a připraveným modelem je čas vyvinout reálné řešení pro produkci.
Co dál?
Další fází je vytvoření reálného řešení pro produkci. Tento krok bude podrobně popsán v následujícím článku této mini série. Zůstaňme v kontaktu, sledujte nás na Linkedin!